Authentication and authorization in a microservice architecture: Part 4 - fetching and replicating authorization data
application architecture architecting securityContact me for information about consulting and training at your company.
The MEAP for Microservices Patterns 2nd edition is now available
This article is the fourth in a series of articles about authentication and authorization in a microservice architecture. The complete series is:
-
Overview of authentication and authorization in a microservice architecture
-
Implementing complex authorization using Oso Cloud local authorization
In Part 3 - implementing authorization using JWT-based access tokens, I defined authorization data as the information a service needs to make an authorization decision. Authorization data falls into three categories:
-
Built-in — the user’s identity and roles that are owned by the IAM service
-
Local — the service’s own data
-
Remote — data owned by other services
Part 3 also introduced four strategies a service can use to obtain remote authorization data:
-
Provide — include the required data in an access token
-
Fetch — call the other service directly, e.g., via its REST API
-
Replicate — maintain a local replica, synchronized using events (e.g., the CQRS pattern)
-
Delegate - eliminates the need for a service to obtain authorization data by delegating authorization decisions to a centralized authorization service, such as Oso Cloud
That article focused on the provide strategy, which simplifies service logic and improves runtime performance but only works when the data is small, stable, and easily obtained by the IAM service.
This article (Part 4) explores the fetch and replicate strategies, which are the two alternatives when provide is not a good fit. Each comes with its own trade-offs in terms of simplicity, runtime coupling, and data freshness.
To make the discussion concrete, we will look at how the RealGuardIO example application implements two operations:
-
disarmSecuritySystem()- disarms a security system if and only if the user is permitted to do so -
findSecuritySystems()- returns a list of the security systems that the user can access
Before diving into the details of each operation, let’s first review the RealGuardIO example application’s architecture.
Overview of the RealGuardIO application’s architecture
RealGuard.io is a fictional commercial real estate security system platform that protects properties such as offices, stores, and warehouses. It manages security systems and provides comprehensive monitoring and protection for physical spaces.
The primary users are employees of Customer organizations whose properties are secured by RealGuardIO systems. These employees can perform operations such as arming and disarming systems, depending on their assigned roles.
The following diagram shows a high-level view of the microservices-based RealGuardIO application:
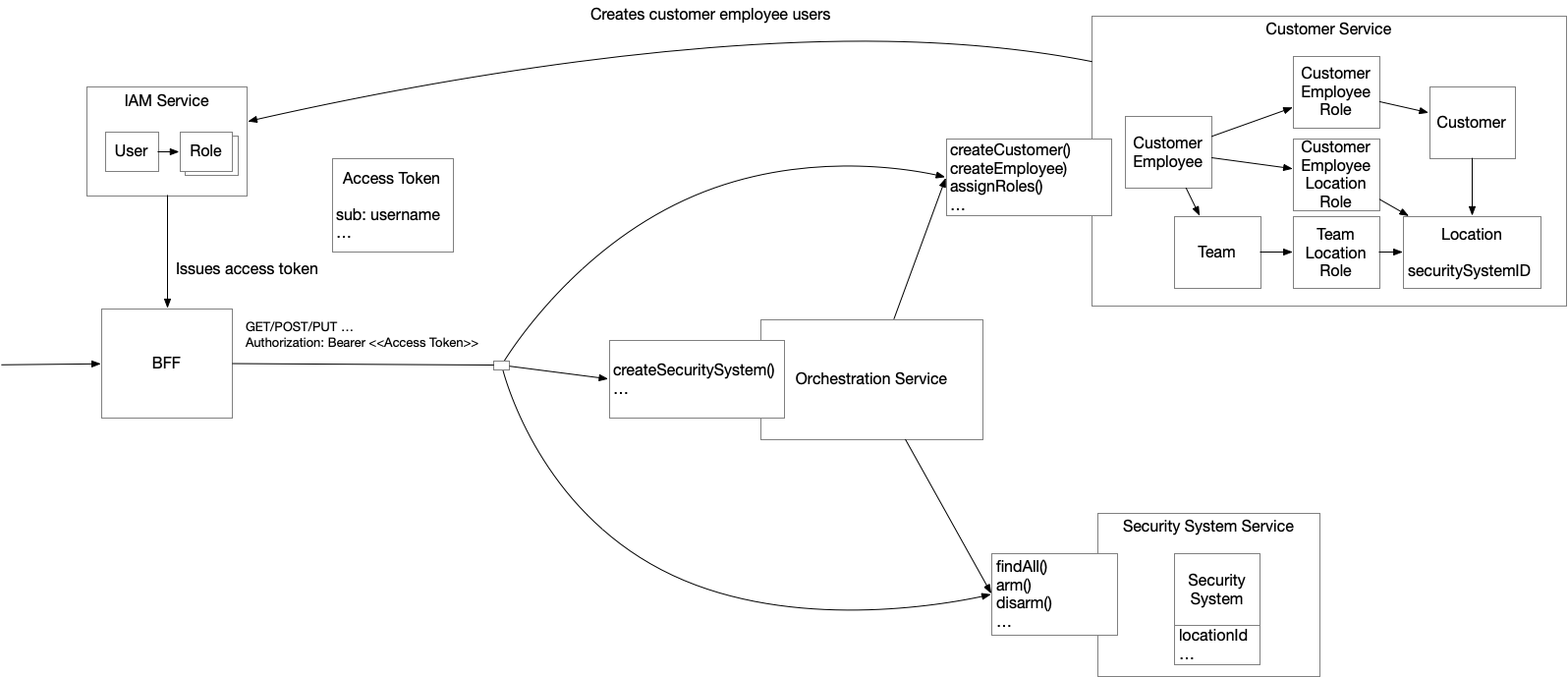
The key parts of the application include:
-
BFF- NextJS-based backend for the front-end that also serves the ReactJS-based UI -
IAM Service- Oauth2/OIDC-based identity service that authenticates users, manages their application-level roles and issues JWT-based access tokens -
Customer Service- manages customers, customer employees and their company-level roles -
Security System Service- manages security systems -
Orchestration Service- coordinates system operations, such ascreateSecuritySystem(), that span multiple services
The authorization challenge in this architecture is that the Security System Service rarely has enough information on its own to make decisions.
Apart from the basic built-in data in the JWT-based access token (user identity and global roles), the relevant authorization data — such as which employees can act at which locations — lives in the Customer Service.
As a result, whenever the Security System Service needs to authorize an operation, it must either fetch the necessary data from the Customer Service or replicate it locally.
The rest of this article explores how these two strategies work in practice.
With the architecture in mind, we can now examine the first strategy for handling remote authorization data: fetching it directly from the Customer Service.
We’ll see how this works in the context of the disarmSecuritySystem() operation.
Implementing disarmSecuritySystem() using fetch
The Security System Service implements operations for managing SecuritySystems including armSecuritySystem() and disarmSecuritySystem() - both of which are invoked by a PUT /securitysystems HTTP request.
To authorize a request, the Security System Service must ensure the user has the required role, e.g. SECURITY_SYSTEM_ARMER or SECURITY_SYSTEM_DISARMER.
That permission can come from:
-
A role assigned at the company level
-
A role assigned at the specific location
-
Membership in a team that has a role at the location
However, the Security System Service only knows about SecuritySystems and their locationID.
All other entities - CustomerEmployee, CustomerEmployeeRole, Customer and Location entities and relationships between - are owned by the Customer Service.
Consequently, the Security System Service must fetch the roles from Customer Service.
Two different ways to implement fetch
There are two different ways for the Security System Service’s operations to fetch the roles from the Customer Service.
Use the Saga pattern
One option is to use the Saga pattern.
A saga is a sequence of transactions in the participating services that’s coordinated through the exchange of messages.
The saga-based version of the disarmSecurityService() would work as follows:
-
Orchestration Serviceinvokes (via asynchronous messaging) theSecurity System Serviceto get thelocationID -
Orchestration Serviceinvokes theCustomer Serviceto verify that the user has permission -
If permitted,
Orchestration Serviceinvokes theSecurity System Serviceto disarm the system
A key benefit of the Saga pattern is reduced runtime coupling.
The Orchestration Service can send back a response to the PUT /securitysystem immediately.
It doesn’t require other services to be simultaneously available.
The downside of this pattern is that it is more complicated and, perhaps, increased latency due to delays processing messages.
Use HTTP GET requests
The second option is for a Security System Service’s operation to retrieve the roles by making a simple HTTP GET request to the Customer Service, propagating the user’s access token.
This is far simpler to implement, but it introduces tight runtime coupling: unlike the Saga pattern, the operation requires both services to be available simultaneously.
For clarity, I’ll briefly describe the HTTP-based approach in more detail.
Fetching roles using HTTP
The following diagram shows the HTTP-based fetch design:
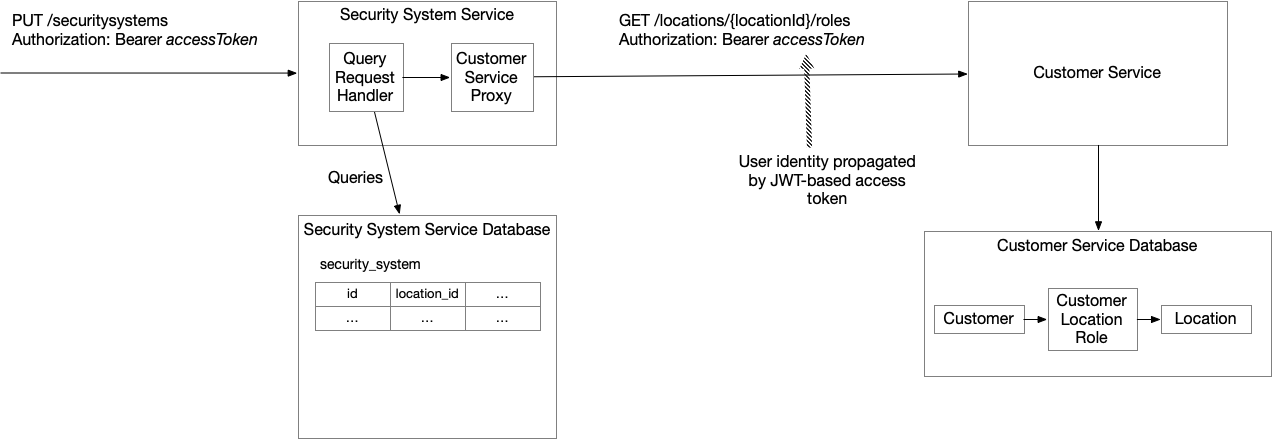
The key ideas are:
-
The
Customer Serviceimplements aGET /locations/{locationId}/rolesendpoint, which returns the set of user roles for that location. -
The
Security System Servicepropagates the user’s identity to theCustomer Serviceby including the access token from the originalPUT /securitysystemsrequest.
This design allows the Security System Service to check whether the user has permission to disarm the system before executing the request.
Benefits and drawbacks of HTTP-based fetch
This approach has the following benefits:
- Simple to implement - just an HTTP proxy class in the
Security System Serviceand an HTTP request handler in theCustomer Service
This approach, however, has the following drawbacks:
-
Tight runtime coupling
-
Overhead of requesting roles each time
To address these drawbacks, let’s turn to the second strategy: replication.
We’ll explore this in the context of the findSecuritySystems() operation.
Implementing findSecuritySystems() using replicate
The findSecuritySystems() system operation returns a list of the security systems that the user is authorized to access.
This data is used to populate the View Security Systems page of the RealGuardIO application’s UI.
Unlike operations, such as armSecuritySystem() or disarmSecuritySystem() that require a specific role, this operation is broader: a customer employee can view a security system if they have any applicable role for its location.
Implementing findSecuritySystems() using fetch
In theory, the Security System Service could use the fetch strategy.
For example, the Security System Service could:
-
Query a
Customer Serviceendpoint for the locations that the user is permitted to access -
Query its own database for
Security Systemsat those locations
Except for the runtime coupling, this approach might work well for users that only have access to a small number of locations. But it’s potentially inefficient for users that have permission to access many locations.
The replicate strategy is faster and less coupled
A better solution is to use the replicate strategy and apply the CQRS pattern to replicate user roles from the Customer Service to the Security System Service.
The Customer service publishes events when user role assignments change.
The Security System Service subscribes to those events and updates local replica tables, such as customer_employee_location_role(userId, location, role).
With this local replica in place, the Security System Service can authorize findSecuritySystems() queries directly in its database, without making remote calls.
The following diagram shows the design:
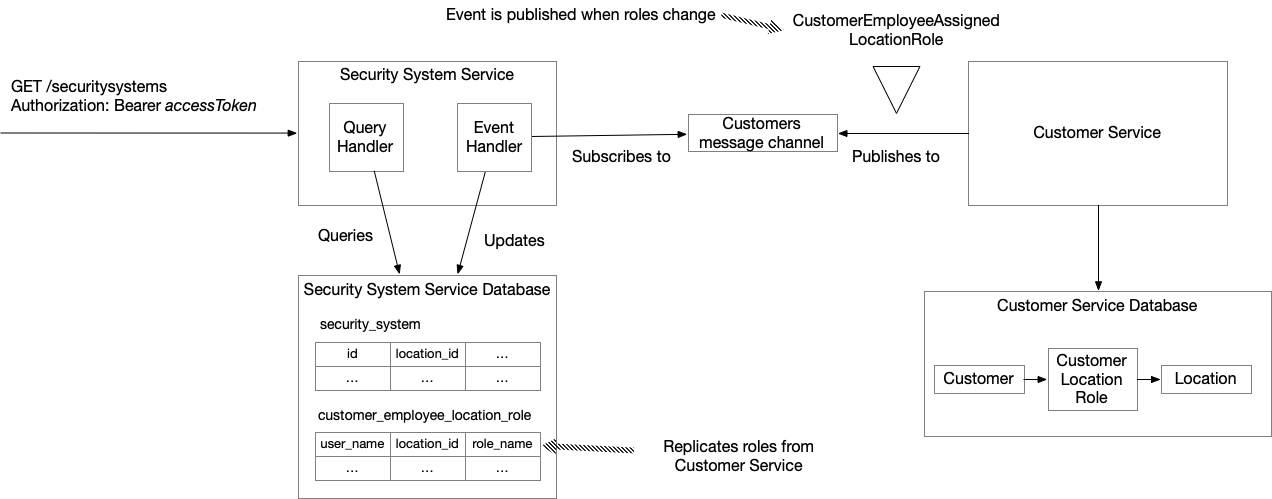
The Customer Service publishes events, such as CustomerEmployeeAssignedLocationRole, to the Customer message channel, which is implemented by an Apache Kafka topic.
The Security System Service has event handlers that subscribe to the channel and update the roles replica tables.
Here’s the example of an SQL SELECT that retrieves the security systems and the user’s roles for each:
SELECT
ss.id AS id,
ss.location_name AS locationName,
ss.state AS state,
ss.location_id AS locationId,
ss.rejection_reason AS rejectionReason,
ss.version AS version,
ARRAY_AGG(DISTINCT celr.role_name
ORDER BY celr.role_name) AS roleNames
FROM security_system ss
JOIN customer_employee_location_role celr
ON celr.location_id = ss.location_id
WHERE celr.user_name = :userName
GROUP BY ss.id
This SELECT statement joins the security_system and customer_employee_location_role tables and returns one row per security system at locations where the specified user has at least one role.
Each row consists of the security_system’s columns and a de-duplicated, ordered array of the user’s role names.
Other operations that need the user’s roles for a SecuritySystem, such as disarmSecuritySystem() can use the same replica.
Benefits and Drawbacks of replication
Using the CQRS pattern to replicate roles has the following benefits:
-
Fast, efficient queries - including joins - against the local database
-
Loose runtime coupling - no need to invoke the
Customer Service
It also has the following drawbacks:
-
Added complexity and overhead due to publishing and consuming events
-
Possibility of stale data due to replication lag
Fortunately, role assignments change infrequently and the dataset is relatively small. It’s unlikely that replicating them will be prohibitively expensive.
Together, fetch and replicate give services two practical ways to access remote authorization data: one favoring simplicity, the other favoring efficiency and runtime decoupling.
Show me the code
The RealGuardIO application (work-in-progress) can be found in the following GitHub repository.
Acknowledgements
Thanks to Hazal Mestci for reviewing this article and providing valuable feedback.
Summary
When authorization data cannot be included in an access token, a service has two main options for obtaining remote authorization data:
-
Fetch — call the service that owns the data
-
A service can fetch remote authorization data using either an HTTP request or the Saga pattern
-
The Saga pattern is more complicated, but it avoids runtime coupling
-
Using an HTTP request is simple, but it introduces runtime coupling
-
-
Replicate — maintain a local copy of the data, synchronized by events (CQRS pattern)
-
The service that owns the authorization data publishes events whenever it changes
-
The service that makes the authorization decisions subscribes to the events and updates a local replica
-
Operations can easily access the replicated information including executing joins against it
-
The main downsides of the replicate strategy is its complexity and overhead along with the possibility of stale data due to replication lag
-
What’s next?
So far, this series has shown how to provide, fetch, and replicate authorization data. Each strategy has different trade-offs for simplicity, runtime coupling, and data freshness.
The final strategy for obtaining remote authorization — delegate — takes a different approach. Instead of obtaining or storing authorization data locally, a service outsources the decision to a centralized authorization service. This approach enables policy-driven, centralized control at the cost of adding a new runtime dependency.
The next two articles will explore how to implement the delegate strategy using the Oso Cloud authorization service.
Need help with modernizing your architecture?
I help organizations modernize safely and avoid creating a modern legacy system — a new architecture with the same old problems. If you’re planning or struggling with a modernization effort, I can help.
Learn more about my modernization and architecture advisory work →







